Back with a post after 6 years of silence. If you had to parse a microsecond-resolution epoch timestamp as quickly as possible, how would you do it? We’ll take a look at using compiler intrinsics to do it in log(n) time.
The problem
Let’s say, theoretically, you have some text-based protocol, or file that contains microsecond timestamps. You need to parse these timestamps as quickly as possible. Maybe it’s json, maybe it’s a csv file, maybe something else bespoke. It’s 16 characters long, and this could also apply to credit card numbers.
timestamp,event_id
1585201087123567,a
1585201087123585,b
1585201087123621,cIn the end you have to implement a function similar to this:
std::uint64_t parse_timestamp(std::string_view s)
{
// ???
}The native solution
Let’s start with what’s available, and compare. We have
std::atoll , a function
inherited from C,
std::stringstream
, the newer C++17
<charconv> header, and
by request
boost::spirit::qi.
I’ll be using Google Benchmark to
measure the performance, and to have a baseline let’s compare against loading
the final result into a register - i.e. no actual parsing involved.
Let’s run the benchmarks! The code is not important here, it just shows what is being benchmarked.
static void BM_mov(benchmark::State& state) {
for (auto _ : state) {
benchmark::DoNotOptimize(1585201087123789);
}
}
static void BM_atoll(benchmark::State& state) {
for (auto _ : state) {
benchmark::DoNotOptimize(std::atoll(example_timestamp));
}
}
static void BM_sstream(benchmark::State& state) {
std::stringstream s(example_timestamp);
for (auto _ : state) {
s.seekg(0);
std::uint64_t i = 0;
s >> i;
benchmark::DoNotOptimize(i);
}
}
static void BM_charconv(benchmark::State& state) {
auto s = example_timestamp;
for (auto _ : state) {
std::uint64_t result = 0;
std::from_chars(s.data(), s.data() + s.size(), result);
benchmark::DoNotOptimize(result);
}
}
static void BM_boost_spirit(benchmark::State& state) {
using boost::spirit::qi::parse;
for (auto _ : state) {
std::uint64_t result = 0;
parse(s.data(), s.data() + s.size(), result);
benchmark::DoNotOptimize(result);
}
}Wow, stringstream is pretty bad. Not that it’s a fair comparison but parsing
a single integer using stringstream is 391 times slower than just loading our
integer into a register. <charconv> and boost::spirit do a lot better by
comparison.
Since we know our string contains the number we’re trying to parse, and we don’t need to do any whitespace skipping, can we be faster? Just how much time is spent in validation?
The naive solution
Let’s write a good old for loop. Read the string character by character, and build up the result.
inline std::uint64_t parse_naive(std::string_view s) noexcept
{
std::uint64_t result = 0;
for(char digit : s)
{
result *= 10;
result += digit - '0';
}
return result;
}That’s actually not bad for a simple for loop. If such a simple solution is able to beat a standard-library implementation, it means there’s quite a lot of effort that goes into input validation. As a sidenote - if you know your input, or can do simpler validation you can get some significant speedups.
For further solutions and benchmarks, let’s ignore the standard library functions. We should be able to go much faster than this.
The brute force solution
If we know it’s 16 bytes, why even have a forloop? Let’s unroll it!
inline std::uint64_t parse_unrolled(std::string_view s) noexcept
{
std::uint64_t result = 0;
result += (s[0] - '0') * 1000000000000000ULL;
result += (s[1] - '0') * 100000000000000ULL;
result += (s[2] - '0') * 10000000000000ULL;
result += (s[3] - '0') * 1000000000000ULL;
result += (s[4] - '0') * 100000000000ULL;
result += (s[5] - '0') * 10000000000ULL;
result += (s[6] - '0') * 1000000000ULL;
result += (s[7] - '0') * 100000000ULL;
result += (s[8] - '0') * 10000000ULL;
result += (s[9] - '0') * 1000000ULL;
result += (s[10] - '0') * 100000ULL;
result += (s[11] - '0') * 10000ULL;
result += (s[12] - '0') * 1000ULL;
result += (s[13] - '0') * 100ULL;
result += (s[14] - '0') * 10ULL;
result += (s[15] - '0');
return result;
}Ok, that’s slightly better again, but we’re still processing a character at a time.
The byteswap insight
Let’s draw out the operations in the unrolled solution as a tree, on a simplified example of parsing ‘1234’ into a 32-bit integer:
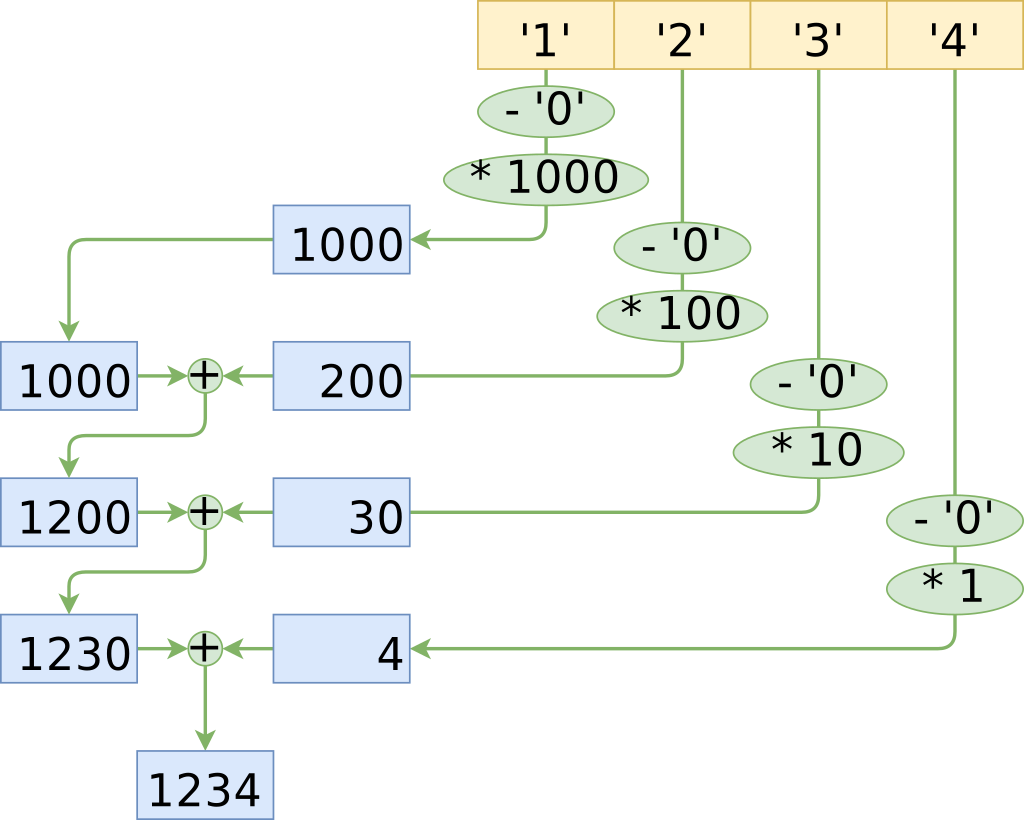
Unrolled solution graph of operations for ‘1234’
We can see that the amount of multiplications and additions is linear with the amount of characters. It’s hard to see how to improve this, because every multiplication is by a different factor (so we can’t multiply “in one go”), and at the end of the day we need to add up all the intermediate results.
However, it’s still very regular. For one thing, the first character in the string is multiplied by the largest factor, because it is the most significant digit.
On a little-endian machine (like x86), an integer’s first byte contains the least significant digits, while the first byte in a string contains the most significant digit.
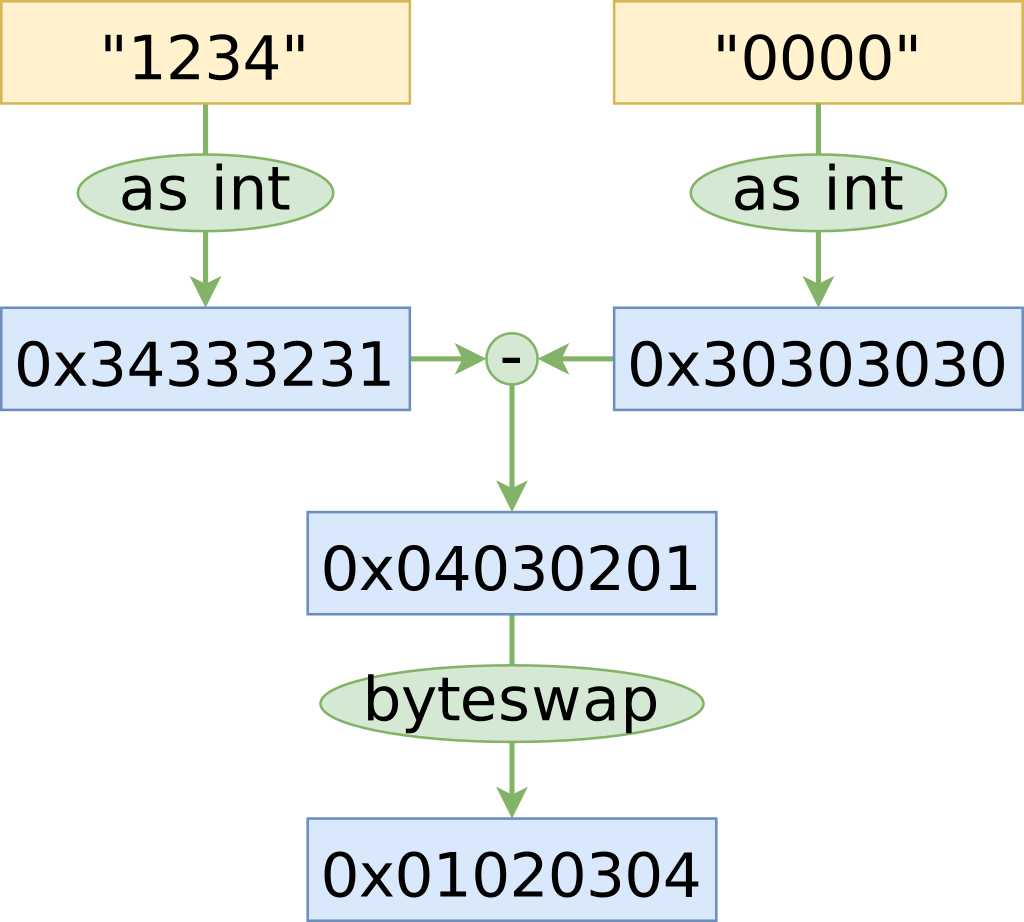
Looking at the string as an integer we can get closer to the final parsed state in fewer operations - see how the hex representation is almost what we want
Now to reinterpret the bytes of a string as an integer we have to use
std::memcpy (to avoid strict-aliasing
violations), and we have compiler
instrinsic __builtin_bswap64 to swap the bytes in one instruction. The
std::memcpy will get optimized out, so this is a win so far.
template <typename T>
inline T get_zeros_string() noexcept;
template <>
inline std::uint64_t get_zeros_string<std::uint64_t>() noexcept
{
std::uint64_t result = 0;
constexpr char zeros[] = "00000000";
std::memcpy(&result, zeros, sizeof(result));
return result;
}
inline std::uint64_t parse_8_chars(const char* string) noexcept
{
std::uint64_t chunk = 0;
std::memcpy(&chunk, string, sizeof(chunk));
chunk = __builtin_bswap64(chunk - get_zeros_string<std::uint64_t>());
// ...
}But now that we have an integer that kind of, sort of looks like what we want, how do we get it across the finish line without too much work?
The divide and conquer insight
From the previous step, we end up with an integer whose bit representation has each digit placed in a separate byte. I.e. even though one byte can represent up to 256 values, we have values 0-9 in each byte of the integer. They are also in the right little endian order. Now we just need to “smash” them together somehow.
We know that doing it linearly would be too slow, what’s the next possibility? O(log(n))! We need to combine every adjacent digit into a pair in one step, and then each pair of digits into a group of four, and so on, until we have the entire integer.
After I posted the first version of this article, Sopel97 on reddit pointed out that the byteswap is not necessary. Combining adjacent digits works either way - their order doesn’t matter. I realized that it helped me with the next insight, but could be omitted for the final code.
The key is working on adjacent digits simultaneously. This allows a tree of operations, running in O(log(n)) time.
This involves multiplying the even-index digits by a power of 10 and leaving the odd-index digits alone. This can be done with bitmasks to selectively apply operations
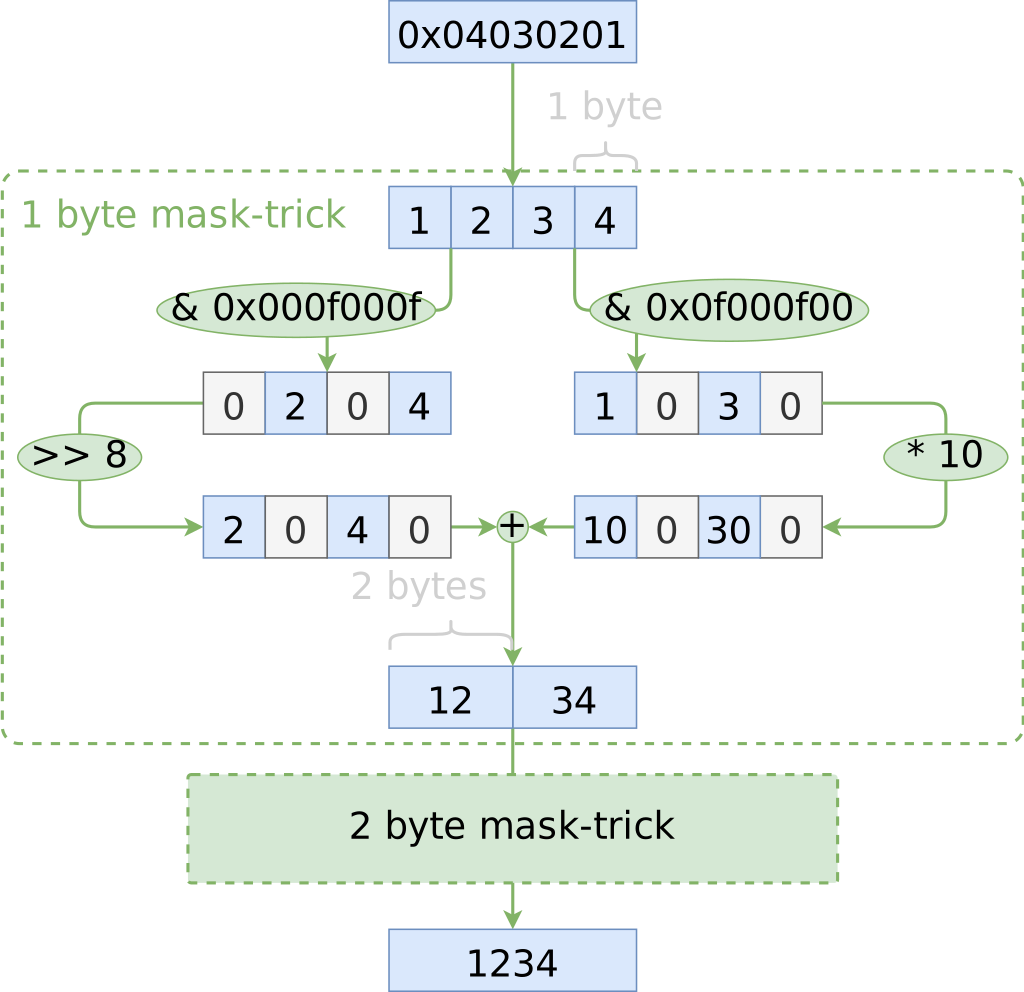
By using bitmasking, we can apply operations to more than one digit at a time, to combine them into a larger group
Let’s finish the parse_8_chars function we started earlier by employing this
masking trick. As a neat side-effect of the masking, we don’t need to subtract
'0', since it will be masked away.
inline std::uint64_t parse_8_chars(const char* string) noexcept
{
std::uint64_t chunk = 0;
std::memcpy(&chunk, string, sizeof(chunk));
// 1-byte mask trick (works on 4 pairs of single digits)
std::uint64_t lower_digits = (chunk & 0x0f000f000f000f00) >> 8;
std::uint64_t upper_digits = (chunk & 0x000f000f000f000f) * 10;
chunk = lower_digits + upper_digits;
// 2-byte mask trick (works on 2 pairs of two digits)
lower_digits = (chunk & 0x00ff000000ff0000) >> 16;
upper_digits = (chunk & 0x000000ff000000ff) * 100;
chunk = lower_digits + upper_digits;
// 4-byte mask trick (works on pair of four digits)
lower_digits = (chunk & 0x0000ffff00000000) >> 32;
upper_digits = (chunk & 0x000000000000ffff) * 10000;
chunk = lower_digits + upper_digits;
return chunk;
}The trick
Putting it all together, to parse our 16-digit integer, we break it up into two
chunks of 8 bytes, run parse_8_chars that we have just written, and benchmark it!
inline std::uint64_t parse_trick(std::string_view s) noexcept
{
std::uint64_t upper_digits = parse_8_chars(s.data());
std::uint64_t lower_digits = parse_8_chars(s.data() + 8);
return upper_digits * 100000000 + lower_digits;
}
static void BM_trick(benchmark::State& state) {
for (auto _ : state) {
benchmark::DoNotOptimize(parse_trick(example_stringview));
}
}Not too shabby, we shaved almost 56% off of the unrolled loop benchmark! Still, it feels like we are manually doing a bunch of masking and elementwise operations. Maybe we can just let the CPU do all the hard work?
The SIMD trick
We have the main insight:
- Combine groups of digits simultaneously to achieve O(log(n)) time
We also have a 16-character, or 128-bit string to parse - can we use SIMD? Of course we can! SIMD stands for Single Instruction Multiple Data, and is exactly what we are looking for. SSE and AVX instructions are supported on both Intel and AMD CPUs, and they typically work with wider registers.
I used the Intel Intrinsics Guide to find the right compiler intrinsics for the right SIMD CPU instructions.
Let’s set up the digits in each of the 16 bytes first:
inline std::uint64_t parse_16_chars(const char* string) noexcept
{
auto chunk = _mm_lddqu_si128(
reinterpret_cast<const __m128i*>(string)
);
auto zeros = _mm_set1_epi8('0');
chunk = chunk - zeros;
// ...
}And now, the star of the show are the madd functions. These SIMD functions do
exactly what we did with our bitmask tricks - they take a wide register,
interpret it as a vector of smaller integers, multiply each by a given
multiplier, and add neighboring ones together into a vector of wider integers.
All in one instruction!
As an example of taking every byte, multiplying the odd ones by 10 and adding
adjacent pairs together, we can use
_mm_maddubs_epi16
// The 1-byte "trick" in one instruction
const auto mult = _mm_set_epi8(
1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10
);
chunk = _mm_maddubs_epi16(chunk, mult);There is another instruction for the 2-byte trick, but unfortunately I could
not find one for the 4-byte trick - that needed two instructions. Here is the
completed parse_16_chars:
inline std::uint64_t parse_16_chars(const char* string) noexcept
{
auto chunk = _mm_lddqu_si128(
reinterpret_cast<const __m128i*>(string)
);
auto zeros = _mm_set1_epi8('0');
chunk = chunk - zeros;
{
const auto mult = _mm_set_epi8(
1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10
);
chunk = _mm_maddubs_epi16(chunk, mult);
}
{
const auto mult = _mm_set_epi16(1, 100, 1, 100, 1, 100, 1, 100);
chunk = _mm_madd_epi16(chunk, mult);
}
{
chunk = _mm_packus_epi32(chunk, chunk);
const auto mult = _mm_set_epi16(0, 0, 0, 0, 1, 10000, 1, 10000);
chunk = _mm_madd_epi16(chunk, mult);
}
return ((chunk[0] & 0xffffffff) * 100000000) + (chunk[0] >> 32);
}0.75 nanoseconds! Beautiful.
Some commenters have complained that this is a toy problem, that there is no input validation or length checking, and that this would only work with a fixed length integer. For one thing, this can be used as a “fast path” when you know your integers are long, and fallback on a simple loop in other cases. Secondly, I bet with a few more clever SIMD instructions you can have something running under 2 nanoseconds complete with validation and length checking.
Conclusion
Compilers are absolutely amazing pieces of technology. They regularly surprise
me (or even blow my mind) at how well they can optimize code and see through
what I’m doing. While preparing the benchmarks for this post, I ran into a
problem - if the string I was trying to parse in the benchmarks was visible to
the compiler in the same compilation unit, no matter what I did, gcc and clang
would evaluate my solutions at compile time and put the final result in the
binary. Even the SIMD implementation! All my benchmarks would come out to be
equivalent to a single mov instruction. I had to put the integer string in a
separate compilation unit, but I bet if I turned on LTO (Link Time
Optimization) the compiler would optimize that away too.
Having said all that, there is a culture of “optimization is the root of all evil”. That handwritten assembly or hand-optimization has no place anymore. That we should just blindly rely on our compilers. I think both positions are complementary - trust your compiler, trust you library vendor, but nothing beats carefully thought out code when you know your inputs and you’ve done your measurements to know it will make a difference.
Imagine your business revolved around parsing a firehose of telemetry data, and
you chose to use std::stringstream. Would you buy more servers or spend a
little time optimizing your parsing?
Post Scriptum
- All benchmarks ran on a 3.8Ghz AMD Ryzen 3900X, on Linux, compiled with GCC 9.2
- Running on a Mac from 2014 wth an Intel processor and compiling with Clang, the non-SIMD trick actually ran slower than the naive loop. The SIMD trick was still fastest.
- I left out table-based parsing methods because I believe they would be slower than the SIMD method here, as they require more data cache usage, and frankly I was lazy to fill out those tables. If people believe the contrary, I can spend some time adding that to these benchmarks.
- You can find the code and the benchmarks here.
- If something is unclear please let me know in the comments - I will try to clarify.
- Reddit discussions can be found on r/programming and r/cpp
- Turns out the byteswap is totally unnecessary! It helped me gain the next insight when thinking through the problem, but the swapping can happen naturally as part of the horizontal additions. I will update the benchmark numbers and update this post in the next few days.
- Also turns out a smart fellow Wojciech Muła already thought of this! . I’m quite happy that we converged on the same methods - down to the same SSE instructions.